In Silico Evaluation of Nonsynonymous Single Nucleotide Polymorphisms in the ADIPOQ Gene Associated with Diabetes, Obesity, and Inflammation
-
Valasala, Harika
-
Department of Biotechnology, K L University, Vaddeswaram, India
-
 Kamma, Sreenivasulu
Department of Biotechnology, K L University, Vaddeswaram, India, Tel: +919 849519527, E-mail: sathwik.kamma@gmail.com
Kamma, Sreenivasulu
Department of Biotechnology, K L University, Vaddeswaram, India, Tel: +919 849519527, E-mail: sathwik.kamma@gmail.com
-
Department of Biotechnology, K L University, Vaddeswaram, India
Abstract: Background: The human ADIPOQ gene encodes adiponectin protein hormone, which is involved in regulating glucose levels as well as fatty acid breakdown. It is exclusively produced by adipose tissue and abundantly present in the circulation, with concentration of around 0.01% of total serum proteins, with important effect on metabolism.
Methods: Most deleterious nonsynonymous single nucleotide polymorphisms in the coding region of the ADIPOQ gene were investigated using SNP databases, and detected nonsynonymous variants were analyzed in silico from the standpoint of relevant protein function and stability by using SIFT, PolyPhen-2, PROVEAN and MUpro, I-Mutant2.0 tools, respectively.
Result: A total of 58 nonsynonymous SNPs consisting of 55 missense variations, 3 nonsense variations were found in the ADIPOQ gene. Next, 14 of the 55 missense variants were predicted to be damaging or deleterious by three different software programs (PolyPhen-2, SIFT, and PROVEAN), and 38 of them were predicted to be less stable (I-Mutant 2.0 and MUpro software). Totally, 10 variants out of 55 missense variants were predicted to be both deleterious and reduce protein stability. Additionally, 3 nonsense variants were predicted to produce a truncated ADIPOQ protein. RMSD and total energy were calculated for 4 nsSNPs out of 10 nsSNPs which were both deleterious and showed a decrease in protein stability.
Conclusion: rs144526209 has high root-mean-square deviation (RMSD) and lower total energy value compared to the native modeled structure. It was concluded that this nsSNP, potentially functional and polymorphic in the ADIPOQ gene, might be associated with diabetes, obesity, and inflammation.
Introduction :
The human ADIPOQ gene is located on chromosome 3q27.3 and encodes a 244 aminoacid protein hormone with four distinct regions and the first one is a short signal sequence which targets the hormone for secretion outside the cell; next one is a short region that varies between species; the third is a 65-amino acid region with similarity to collagenous proteins; the last is a globular domain, to form these distinct regions and a number of post-translational modifications are required. It is exclusively produced by adipocytes and also froms the placenta in pregnancy and circulates high concentrations in healthy adults and is generally higher in females than males. This sexual differentiation has been attributed to the effect of testosterone on adiponectin secretion.
It is the most abundant circulating hormone secreted by the adipocytes, with putative insulin sensitizing, anti-inflammatory, and antiatherosclerotic properties. In a normal pregnancy, the maternal adiponectin circulating concentration increases in the first half of the pregnancy and then decreases proportionally to weight gain and physiological insulin resistance worsening. Newborn’s adiponectin concentrations are higher than maternal circulating levels during pregnancy. Overall, it suggests that adiponectin, in addition to potentially linking excess adiposity to the risk of insulin resistance and type 2 diabetes, has a potential role in pregnancy and fetal growth 1. Meller et al studied on leptin receptor (LEPR A-D) and adiponectin receptor (ADIPOR 1 & 2) and observed an association between GDM diagnosis and leptin mRNA expression in placental tissues 2. In screening for GDM by maternal characteristics, the detection rate was 61.6% at a false-positive rate of 20% and the detection increased to 74.1% by the addition of adiponectin and sex hormone binding globulin 3. A multi-SNP genotype risk score that accounted for 5% of the variance of adiponectin levels exhibited significant association with T2D and markers of insulin resistance, suggesting a shared allelic architecture of adiponectin and other metabolic traits 4.
As genomic variations among people, Single Nucleotide Polymorphisms (SNPs) exist throughout the genome and can be divided into several groups. Among the different kinds of SNPs, a nonsynonymous SNP in the coding region of a gene is important because it alters the amino acid composition; consequently, such alterations can have an impact on protein structure, function, and subcellular localization. Although pinpointing the effects of the many nonsynonymous SNPs using biochemical analyses is challenging, computational analysis tools predicting their effect on protein activity and stability have been recently developed, such as Polymorphism phenotyping v2 (PolyPhen-2) 5, Sorting Intolerant From Tolerant (SIFT) 6, Protein Variation Effect Analyzer (PROVEAN) 7, I-Mutant 2.0 8, and MUpro 9 software. The gene was investigated for variants that predispose to type-2 diabetes and insulin sensitivity which leads to Gestational Diabetes Mellitus. Several single nucleotide polymorphisms mutations in the ADIPOQ gene, G84R and G90S mutants, associated with diabetes and hypoadiponectinemia (Vasseur et al, 2002), did not form HMW multimers. R112C and I164T mutants, associated with hypoadiponectinemia, did not assemble into low-molecular-weight trimers, resulting in impaired secretion from the cell 10 associated with type-2 diabetes and obesity. Thus, in the present study, an attempt was made to search for nonsynonymous SNPs in the ADIPOQ gene using genome databases and investigate the impacts of nonsynonymous SNPs on adiponectin protein function and stability using computational tools.
Materials and Methods :
Retrieval of nonsynonymous SNPs: Data on nonsynonymous variations of the ADIPOQ gene were collected from the database of SNPs (dbSNP) located on the homepage of the National Center for Biotechnology Information website (http:// www.ncbi.nlm.nih.gov/SNP/) and from the Ensembl genome browser (http://www.ensembl.org/index.html). The reference Transcript ID and the reference protein ID of ADIPOQ are NM_004797 and NP_004788, respectively.
SIFT prediction: The Sorting Intolerant from Tolerant (SIFT) algorithm predicts the effect of coding variants on protein function based on the degree of conservation of aminoacid residues in sequence alignments derived from closely related sequences 6. It was first introduced in 2001, with a corresponding website that provides users with predictions on their variants. Since its release, SIFT has become one of the standard tools for characterizing missense variation. SIFT is based on the premise that protein evolution is correlated with protein function. Variants that occur at conserved alignment positions are expected to be tolerated less than those that occur at diverse positions. The algorithm uses a modified version of PSIBLAST 11 and Dirichlet mixture regularization 12 to construct a multiple sequence alignment of proteins that can be globally aligned to the query sequence and belong to the same clade. The underlying principle of this program is that it generates alignments with a large number of homologous sequences and assigns scores to each residue, ranging from zero to one. SIFT scores 13 are categorized as potentially intolerant (0.051-0.10), intolerant (0.00-0.05), tolerant (0.201-1.00) or borderline (0.101-0.20). The higher the tolerance index of a particular amino acid substitution, the lesser is its likely impact (Table 1).
PROVEAN prediction: PROVEAN (Protein Variation Effect Analyzer) predicts the functional impact for all classes of protein sequence variations not only single aminoacid substitutions but also insertions, deletions, and multiple substitutions on the alignment-based score 7. The score measures the change in sequence similarity of a query sequence to a protein sequence homolog between without and with an amino acid variation of the query sequence. If the PROVEAN score ≤-2.5, the protein variant is predicted to have a "deleterious" effect, while if the PROVEAN score is >-2.5, the variant is predicted to have a "neutral" effect (Table 1). Both types of softwares are available on the homepage of the J. Craig Venter Institute; the SIFT tool is at http://sift.jcvi.org, and the PROVEAN tool is at http://provean.jcvi.org.
PolyPhen-2 prediction: PolyPhen 14 is a computational tool for identification of potentially functional nsSNPs. Predictions are based on a combination of phylogenetic, structural, and sequence annotation information characterizing a substitution and its position in the protein. For a given aminoacid variation, PolyPhen performs several steps: (a) extraction of sequence-based features of the substitution site from the UniProt database, (b) calculation of profile scores for two aminoacid variants, and (c) calculation of structural parameters and contacts of a substituted residue. PolyPhen scores were classified as "benign", "possibly damaging" or "probably damaging" 13 (Table 1). Input options for the PolyPhen server are protein sequence or accession number together with sequence position with two aminoacid variants.
Mutant2.0: I-Mutant2.0 (http://folding.biofold.org/i-mutant/i-mutant2.0.html) is a support vector machine-based tool for the prediction of protein stability changes upon nonsynonymous variations 8. The tool evaluates the stability change upon nonsynonymous SNP starting from the protein structure or from the protein sequence. The DDG value (difference in free energy of mutation) is calculated from the unfolding Gibbs free energy value of the variant protein minus the unfolding Gibbs free energy value of the wild type (kcal/mol), and scores <0 are predicted by the algorithm to indicate decreased stability, whereas scores >0 are considered to indicate increased stability (Table 2).
MUpro: MUpro (http://www.ics.uci.edu/~baldig/mutation. html) is also a support vector machine-based tool for the prediction of protein stability changes upon nonsynonymous SNPs 9. The value of the energy change is predicted, and a confidence score between -1 and 1 for measuring the confidence of the prediction is calculated. A score <0 means the variant decreases the protein stability; conversely, a score >0 means the variant increases the protein stability (Table 2).
Modeling of mutant structures and calculation of their RMSD values: To evaluate the structural stability between the native and mutant, protein structure analysis was performed based on the availability of X-ray crystallographic structure of a protein in any database. In case of ADIPOQ, 3D crystallographic structure was not available in PDB. Therefore, a structure of human adiponectin globular domain was created by homology modeling using a 30 kDa adipocyte complement-related protein precursor -ACRP30 (PDB 1C28), the most suitable template identified by blast searches, as the template showed 91.97% of sequence identity 15. Mutant models were prepared by FASTA format sequence submitted in SWISS-MODEL expasy (http:// swissmodel.expasy.org/). Energy minimization was done for both mutant and native models through DESMOND server with 2000 iterations. Further free energy and RMSD values were calculated by swiss PDB viewer and SuperPose online server, respectively.
Results :
SNP analysis: By examining ADIPOQ gene using the dbSNP and HGVD databases, a total of 58 nonsynonymous SNPs were found. These SNPs consist of 55 missense variations and 3 nonsense variations.
Prediction of deleterious nsSNPs: In PolyPhen-2 analysis, 26 (47.8%) of the 55 variants were predicted to be probably damaging, and the others were predicted to be benign or possibly damaging, whereas in SIFT, 18 variants (32.7%) were predicted to be damaging, and others were predicted to be tolerated. By PROVEAN analysis, 27 variants (49.1%) were predicted to be deleterious, but the others were neutral (Figure 1). Among the above, 16 (29%) common ADIPOQ gene variants, namely, c.133G>C (p.Gly45Arg), c.140C>T (p.Pro47Leu), c.143G>A (p. Gly48Asp), c.161G>T (p.Gly54Val), c.163C>T (p.Arg 55Cys), c.223G>T (p.Gly75Cys), c.250G>A (p.Gly 84Arg), c.268G>A (p.Gly90Ser), c.334C>T (p.Arg 112Cys) c.335G>C (p.Arg112Leu), c.335G>T (p.Arg 112Pro), c.353G>A (p.Gly118Glu), c.425A>T (p.His 142Leu), c.593C>T (p.Ser198Phe), c.595G>A (p.Gly 199Ser), andc.626A>G (p.Asp209Gly) were found.
Identification of functional nsSNP: Changes in the protein stability of missense variants were examined using I-Mutant 2.0 and MUpro software (Figure 2). In I-Mutant 2.0 prediction, 47 (85.4%) of 55 variants and in case of MUpro analysis, 41 (74.5%) variants were predicted to decrease protein stability. A total of 37 variants (67.2%) out of the 55 missense variants, including 10 out of 16 common damaging or deleterious variants namely c.133G>C (p.Gly45Arg), c.143G>A (p.Gly48Asp), c.163C>T (p.Arg55Cys), c.223G>T (p.Gly75Cys), c.250G>A (p.Gly84Arg), c.268G>A (p.Gly90Ser), c.334C>T (p.Arg112Cys) c.335G>C (p.Arg112Leu), c.595G>A (p.Gly199Ser), and c.626A>G (p.Asp209Gly) as determined using PolyPhen-2, SIFT, and PROVEAN software applications, were predicted to be less stable using both the I-Mutant 2.0 and the MUpro software.
Three nonsense variations in the ADIPOQ gene were predicted to produce a truncated ADIPOQ protein. The c.274C>T (p.Arg92Ter, c.635G>A (p.Trp212Ter), and c.658G>T (p.Glu220Ter) variants predicted to truncate the protein production are given in table 3.
Modeling of mutant proteins: The mutations which were both deleterious with less protein stability in the ADIPOQ gene were executed by swiss PDB viewer independently to get modeled structures. Then, energy minimization was achieved by DESMOND server for native and mutant structures. The total energy and RMSD values for the native and mutated structures are given in table 4. The higher the RMSD value is, the more the deviation between the two structures is, which in turn changes their functional activity. The total energies and RMSD values were higher for one mutant structure compared to the homology modeled structure (Table 4); these nsSNPs could affect the structure of the proteins.
Discussion :
Our analysis revealed 58 nonsynonymous variants out of 55 missense and other three were nonsense variants. 10 variants namely c.133G>C (p.Gly45Arg), c.143G>A (p.Gly48Asp), c.163C>T (p.Arg55Cys), c. 223G>T (p.Gly75Cys), c.250G>A (p.Gly84Arg), c.268 G>A (p.Gly90Ser), c.334C>T (p.Arg112Cys), c.335 G>T (p.Arg112Pro), c.595G>A (p.Gly199Ser), andc. 626A>G (p.Asp209Gly) out of 55 missense variants showed deleterious scores by SIFT, PROVEAN, PolyPhen (Table 1) and decreasing the protein stability upon their aminoacid changes by I Mutant 2.0 and MUpro (Table 2). Mutant models were built by swiss model by using template 1c28.A to 4 nsSNPs out of 10 nsSNPs which is common to both deleterious and less protein stability due to the template predicted by complement component C1q domain region of the ADIPOQ protein only. Further energy minimization was done by Desmond server and total energy was calculated by swiss PDB viewer and RMSD values were calculated by SuperPose online server. The RMSD value of mutant (G199S) model was high compared to the native model. In case of total energy, mutant models show lower energy than the native models as given in table 4. Three nonsense variations in the ADIPOQ gene were predicted to produce a truncated protein. The c.274C>T (p.Arg92Ter) variant in collagen region, c.635G>A (p.Trp212Ter), and c.658G>T (p.Glu220 Ter) variants in complement component C1q domain were predicted to truncate the protein production; these results suggested that p.Arg92Ter nonsense variant truncates the whole region of the complement C1q domain and the remaining two variants such as p.Trp212Ter and p.Glu220Ter terminate the partial complement C1q domain of the ADIPOQ protein synthesis.
Adiponectin, an endogenous insulin-sensitizing hormone and the most abundant adipokine produced especially by the human adipose tissue, is linked to metabolic syndrome, type-2 diabetes, insulin resistance, obesity, and inflammation as well as several types of cancers. Adiponectin has anti-inflammatory and antilipogenic effects, while Tumor Necrosis Factor alpha (TNF-alpha) reduces insulin sensitivity and has proinflammatory effects 16 . In general, a lower level of adiponectin concentration in blood circulation correlates with an increased body mass index (BMI) and insulin resistance. A higher BMI leads to a higher risk for obesity. Greater insulin resistance increases risk for type 2 diabetes mellitus (T2DM). Two particular variants such as rs17300539 and rs266729 in the promotor region of the ADIPOQ cause cells to make less adiponectin. Decreased adiponectin means less glucose utilization and less efficient fat burning and therefore a greater risk of developing obesity and T2DM 17.
Genetic factors such as single nucleotide polymorphisms in the adiponectin gene and environmental factors such as a high-fat diet and inactivity are associated with low adiponectin concentrations and may contribute to the development of insulin resistance, type 2 diabetes, and atherosclerosis. Adiponectin automatically self-associates into larger structures with high molecular weight. Initially, three adiponectin molecules bind together to form a homotrimer and they continue to self-associate and form hexamers or dodecamers. High-molecular-weight adiponectin was further found to be associated with a lower risk of diabetes with similar magnitude of association as total adiponectin 18. However, coronary artery disease has been found to be positively associated with high-molecular-weight adiponectin, but not with low-molecular-weight adiponectin 19. Evaluation of adiponectin levels with the ratio of High Molecular Weight (HMW)/Low Molecular Weight (LMW) and (MMW) and consideration of different ethnic genetic backgrounds are of importance in the translational research of adiponectin. Two novel nonsynonymous ADIPOQ variations i.e. P32L, and R55C were achieved using an extreme phenotype sequencing approach. Individuals with these novel variations had low adiponectin and exhibited reduced HMW structures compared to individuals without these variations. Although each variation is present in the heterozygous state, dominant negative effects may exist 20. The high-molecular-weight isoform adiponectin is believed to be the biologically active form that activates downstream events in both skeletal muscle and the liver 21. Several rare ADIPOQ gene mutations affecting the multimerization and consequently the biological function of the protein have been characterized. For example, the Arg112Cys and Ile164Thr mutants do not assemble into trimers, leading to the clinic symptom hypoadiponectinemia. The Gly84Arg and Gly 90Ser mutants are able to assemble into trimers and hexamers but are unable to form the high-molecular-weight multimers, leading directly to diabetes 21. R55H, G84R, and G90S variations did not disturb adiponectin trimeric and hexameric formations but obstructed their multimerization. These variants are not close to interdisulfide bond forming site (Cys36) and they were still capable of forming hexamers. However, they might cause conformational change and conceal the remaining free thiol from interacting with other hexamers 15.
Therefore, plasma/serum adiponectin levels and genomic DNA polymorphisms in the ADIPOQ gene can be used as the biomarkers for early diagnosis and clinical prediction of diabetes, obesity, diabetic complications and other metabolic disorders.
Conclusion :
In the present study, a total of 58 nonsynonymous SNPs in ADIPOQ gene involved in diabetes, obesity and inflammation were analyzed. Out of the 58 nsSNPs, 55 were found to be missense variations and 3 were nonsense variations. Further in silico analysis using different softwares (PolyPhen 2, SIFT and PROVEAN) predicted that 16 of the 55 missense variants were damaging or deleterious. Also, in silico analysis (I-Mutant 2.0 and MUpro) was carried out and 37 variants were identified that were predicted to be less stable. In addition, 3 nonsense variants were predicted to lead to the production of a truncated ADIPOQ protein. Further total energy and RMSD values were calculated for 4 nsSNPs out of 10 nsSNPs which were both deleterious and showed a decrease in protein stability. Mutant model G199S (rs144526209) showed high RMSD with low total energy which can be considered as the most deleterious variant of ADIPOQ gene.
Acknowledgement :
The authors are thankful for management of K L University for providing the facilities to undertake this study.
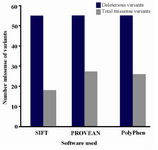
Figure 1. Graphical representation of deleterious variations.
|
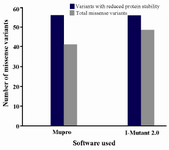
Figure 2. Graphical representation of protein stability analysis.
|
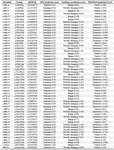
Table 1. PolyPhen-2, SIFT, and PROVEAN results for the 55 missense variants of the ADIPOQ gene
Reference transcript ID, NM_004797.
Reference protein ID, NP_001171271.
|

Table 2. I-Mutant and MUpro results for the 55 missense variants of the ADIPOQ gene
Reference protein ID, NP_001171271.
|
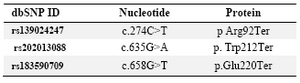
Table 3. Summary of nonsense variations of ADIPOQ gene
Reference protein ID, NP_001171271.
|
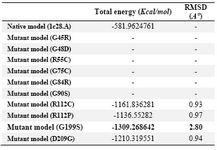
Table 4. RMSD and total energy of modeled structure and its mutant forms
|
|